Ask Why!Finding motives, causes, and purpose in data science
Yanir Seroussi
yanirseroussi.com | @yanirseroussi | linkedin.com/in/yanirseroussi
Note: This talk is also available as a blog post and as a video.
Thanks Phil!

Are you doing anything on 6th May next year? I'm organising an event and need a passionate data scientist to tell it as it is! Let me know if you are interested, and what you would like to talk about - hopefully something technical and thought provoking.
General outline
Asking why to:
| Uncover stakeholder motives | [telling it as it is] |
| Infer causal structures | [hopefully technical] |
| Find your purpose | [hopefully thought-provoking] |
Thanks Eugene and Fabian! [Sydney Special]
Hi Fabian and Yanir,
Time for Yanir to tell us something new. Could you please arrange for him to present.
Cheers,
Eugene
Uncovering stakeholder motives

A not-so-imaginary scenario...
Client: I need a model to predict churn.
Younger me: Sure, I'll plow through your data and use deep learning to build the best model ever! It's going to be awesome!
...a few weeks later...
Younger me: The model is ready! It's super-accurate, with the most predictive feature being tenure with the company.
Client: Thanks! We don't really have time to use this model at the moment, as our churn rates are actually pretty low. Let's talk again when this becomes a problem.
Better ask why
Client: I need a model to predict churn.
Current me: Why do you need a model to predict churn? What are you going to do with it?
...a few minutes later...
Current me: So what you really want is to reduce churn, because you assume that preventable churn is costing you $10M per year. Hence, you'd be willing to pay for a system that not only predicts churn, but also schedules the most effective interventions to prevent it based on the customer's personal circumstances.
Client: Correct! Please build me this magical system!
Possible answers to why do you need a model?
It'll look good on my performance review
Run away!
We always use a model, even if using it is worse than random
Run away, even faster. Sounds like they're unlikely to see business value in data science.
We want to understand what's causing churn
Be careful with your modelling, e.g., short tenure doesn't necessarily cause churn.
Inferring causal structures

Classic example: Simpson's Paradox
| Population size | Recovered? (E) | Recovery rate | ||
| Everyone | ||||
| Treated | C | 40 | 20 | 0.5 |
| Untreated | ¬ C | 40 | 16 | 0.4 |
| Females | ||||
| Treated | F, C | 10 | 2 | 0.2 |
| Untreated | F, ¬C | 30 | 9 | 0.3 |
| Males | ||||
| Treated | ¬F, C | 30 | 18 | 0.6 |
| Untreated | ¬F, ¬C | 10 | 7 | 0.7 |
Should we prescribe the treatment to a patient?
If we don't know their gender...Yes! P(E|C) > P(E|¬C)
If they're female...No! P(E|C, F) < P(E|¬C, F)
If they're male...No! P(E|C, ¬F) < P(E|¬C, ¬F)

Pearl: Causal assumptions are essential
Assumption: Gender affects treatment uptake and recovery
→ Follow the gender-specific measures and never prescribe C
Different scenario: F is high blood pressure, the treatment affects blood pressure, and blood pressure affects recovery
→ Follow the aggregated measures and always prescribe C
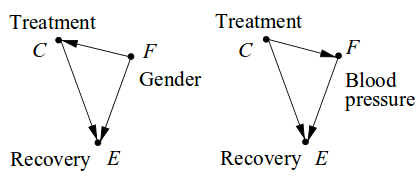
Generally: The decision whether to use F to predict E can't only depend on the data
Some flavours of causality
- Graphical models: Pearl and many others
- Vanilla Bayesian networks: Time as an afterthought
- Dynamic Bayesian networks: Hard to model long-term effects and non-discrete time intervals
- Granger-causality: Can past values of X be used to forecast Y?
- Not really causality, more like temporal correlation
- Kleinberg: Temporal logic
- Doesn't shy away from philosophical discussions
- Still early days, practical use unclear
Cause of frustration #1:
No single definition
There is simply no unified philosophical theory of what causes are, and no single foolproof computational method for finding them with absolute certainty. What makes this even more challenging is that, depending on one's definition of causality, different factors may be identified as causes in the same situation, and it may not be clear what the ground truth is.
Cause of frustration #2:
Need for untested assumptions
We know, from first principles, that any causal conclusion drawn from observational studies must rest on untested causal assumptions. Cartwright (1989) named this principle 'no causes in, no causes out,' which follows formally from the theory of equivalent models (Verma and Pearl, 1990); for any model yielding a conclusion C, one can construct a statistically equivalent model that refutes C and fits the data equally well.
Cause of frustration #3:
Unreasonable people
Our findings parallel those of previous work and show that endorsement of free-market economics predicted rejection of climate science. Endorsement of free markets also predicted the rejection of other established scientific findings, such as the facts that HIV causes AIDS and that smoking causes lung cancer. We additionally show that, above and beyond endorsement of free markets, endorsement of a cluster of conspiracy theories (e.g., that the Federal Bureau of Investigation killed Martin Luther King, Jr.) predicted rejection of climate science as well as other scientific findings. Our results provide empirical support for previous suggestions that conspiratorial thinking contributes to the rejection of science.
Why bother with causality then?
- Properly encode causal assumptions
- Form plausible explanations
- Generate stable predictions
- Schedule effective interventions
- Deal with political implications
Coming up with causal assumptions [Sydney Special]
Bradford Hill criteria for separating association from causation
| Strength | How strong is the association? |
| Consistency | Has association been repeatedly observed in various cases? |
| Specificity | Are specific X instances associated with specific Y instances? |
| Temporality | Do we know that X leads to Y or are they observed together? |
| Biological gradient | Is Y a known function of X, e.g., dose-response curve? |
| Plausibility | Is there a mechanism that can explain how X causes Y? |
| Coherence | Does the association conflict with our current knowledge? |
| Experiment | Can controlled experiments support a causal hypothesis? |
| Analogy | Do we know of any similar cause-and-effect relationships? |
Experiments are great, but not perfect [Sydney Special]
If you can run an experiment, you should!
A/B testing: Selection biases, multiple comparisons
Smoking/Climate/Nutrition: Practicality, corporate interests
Well-designed experiments may yield strange results
Remote intercessory prayer said for a group of patients is associated with a shorter hospital stay and shorter duration of fever in patients with a bloodstream infection, even when the intervention is performed 4–10 years after the infection.
Finding your purpose

My path and motivations so far
- Technion BSc: Interesting, portable profession
- Intel: Just wanted to write software
- Qualcomm: Wanted to write more interesting software
- Monash PhD: Australia, interested in AI & NLP
- Google: Wanted Australian work experience, pad CV
- Giveable: Australia, early-stage startup, PhD-related
- Next Commerce: Sydney, data science, retain Giveable work
- Consulting/own projects: Lifestyle, independence
- Car Next Door: Values, interests, long-term lifestyle
Natural progression
Are you building generalised useless models? Why do you bother?
- No objective definition of meaning
- Totally fine to be doing it for money/experience, just be honest
- Money doesn't necessarily compensate for Dilbertian suffering and lack of pride in your work
- Most data scientists have a choice – make sure you choose well